
A Creative Thinker & Challenge Accepter
I’m a passionate, innovative engineer who genuinely enjoys exploring the world of virtualized
servers and containers — always pushing the boundaries of what’s possible. My skills have been
sharpened through dedicated self-learning and hands-on experience deploying diverse web projects,
networks, and systems.
If you’re reading this, I’d be thrilled to bring that expertise, curiosity, and problem-solving
mindset to your team and contribute to your organization’s success.
My Services
Pick the kind of DevOps support that fits where your platform is today.
Social Presence & Community
We help define themes, create publishing rhythms, and set up processes that make content production easier. Engagement guidelines and influencer workflows are included when relevant.

Infrastructure Optimization and Scalability Services
Is your infrastructure holding you back? Let me optimize and scale your systems for peak performance and efficiency. From cloud migrations to resource allocation, I’ll tailor solutions to fit your unique needs, one-on-one.

Network Security and Performance Enhancement
Concerned about network vulnerabilities? With my personalized network security services, rest assured your data stays safe and your connections strong. Together, we’ll fortify your defenses and ensure smooth, secure operations.
Database Management and Optimization Services
Struggling with sluggish databases? As your dedicated DBA, I’ll fine-tune your databases for lightning-fast performance and rock-solid reliability. From migrations to disaster recovery, trust me to keep your data humming along smoothly.
Social Presence & Community
We help define themes, create publishing rhythms, and set up processes that make content production easier. Engagement guidelines and influencer workflows are included when relevant.
Advertising Management
We create organised campaign structures, test creative variations, and maintain a regular review rhythm. The emphasis is on understanding what’s resonating and making thoughtful adjustments.
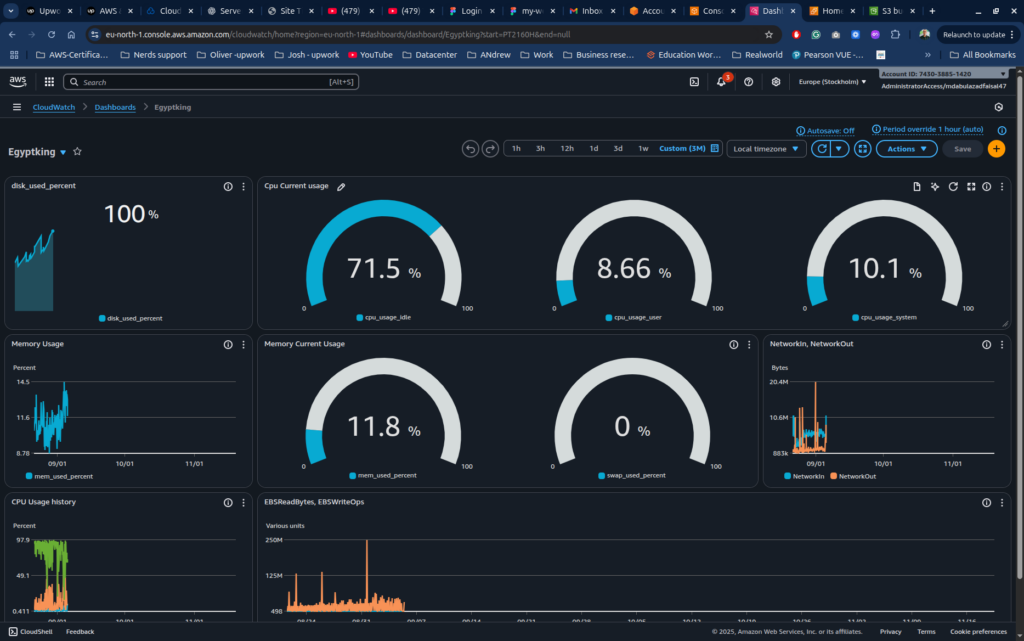
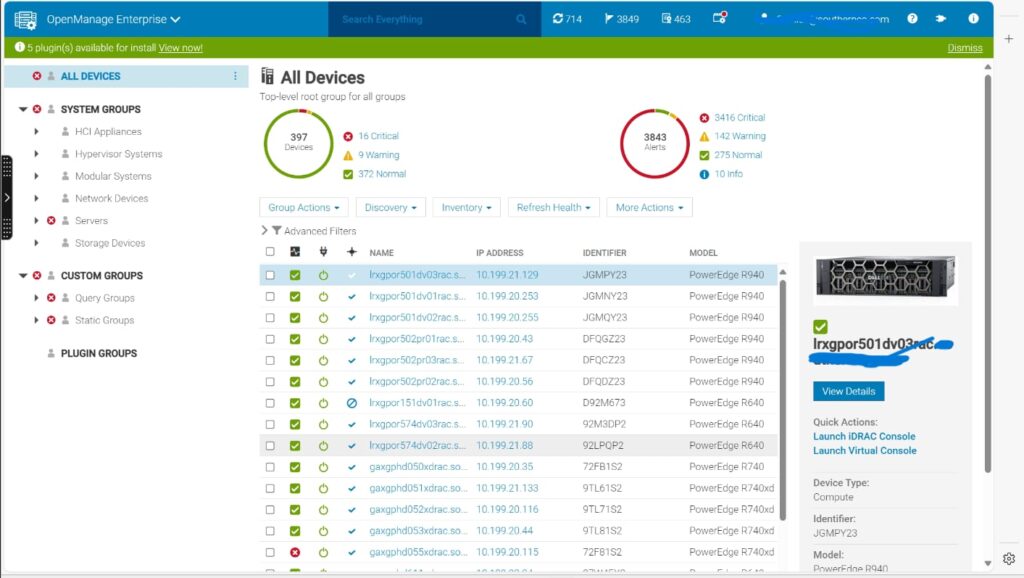
AWS CloudWatch Monitoring & Alerting for High-Traffic Production Applications
Two rapidly scaling online platforms — a gaming application EgyptKingCrash and a microservices-based sportsbook platform Rise & Hustle — required robust observability and real-time performance visibility to maintain continuous uptime under heavy user load.While the infrastructure was functional, monitoring lacked depth, proactive alerts were limited, and the engineering team had no single unified view of...
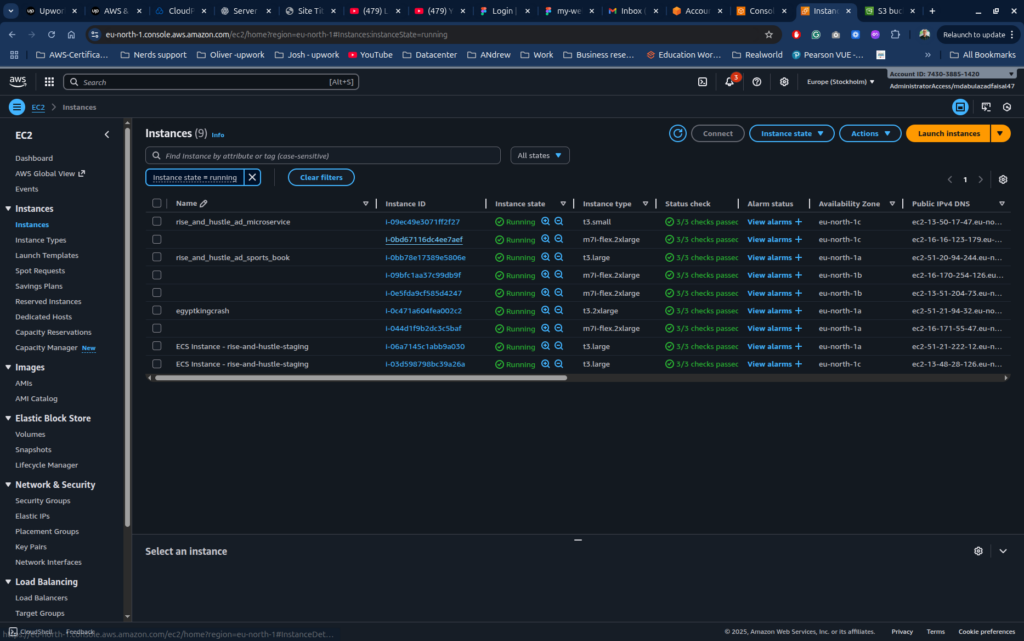
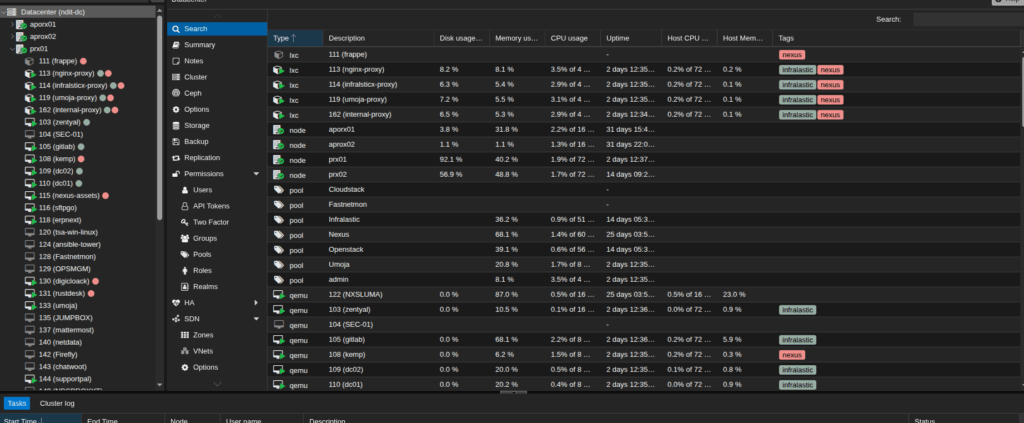
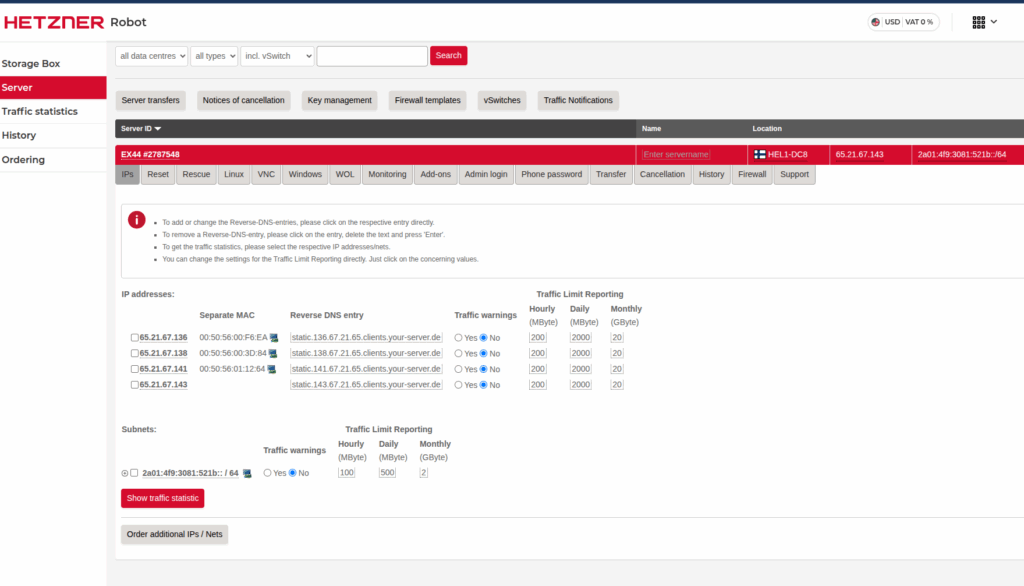
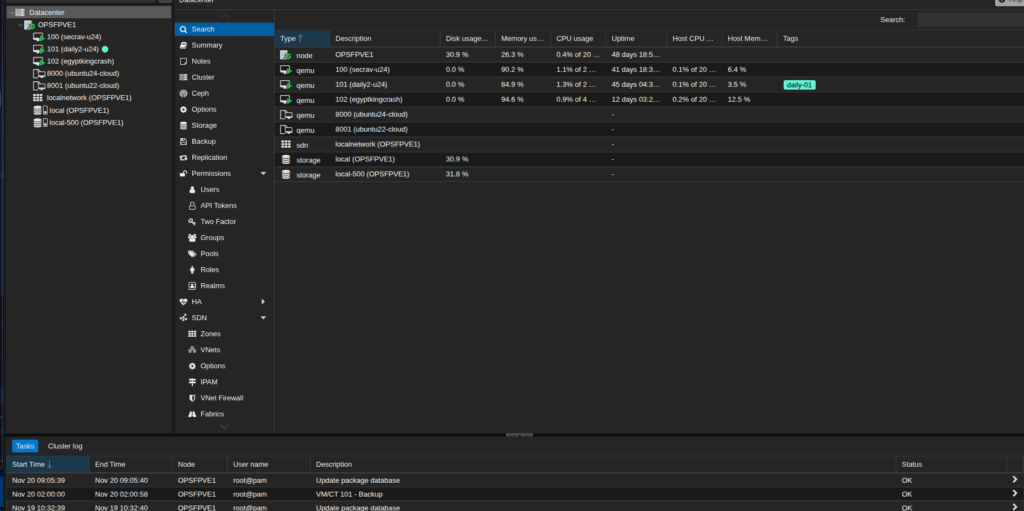
Proxmox HA Hybrid Environment for High Availability Across On-Prem and Cloud
A rapidly growing technology company needed an infrastructure that could support mission-critical workloads without downtime, while also reducing dependency on a single location. Their on-premise Proxmox servers were reliable but lacked cross-site high availability, and the team wanted to incorporate cloud-based redundancy to ensure business continuity. They approached us to design and build a Proxmox...
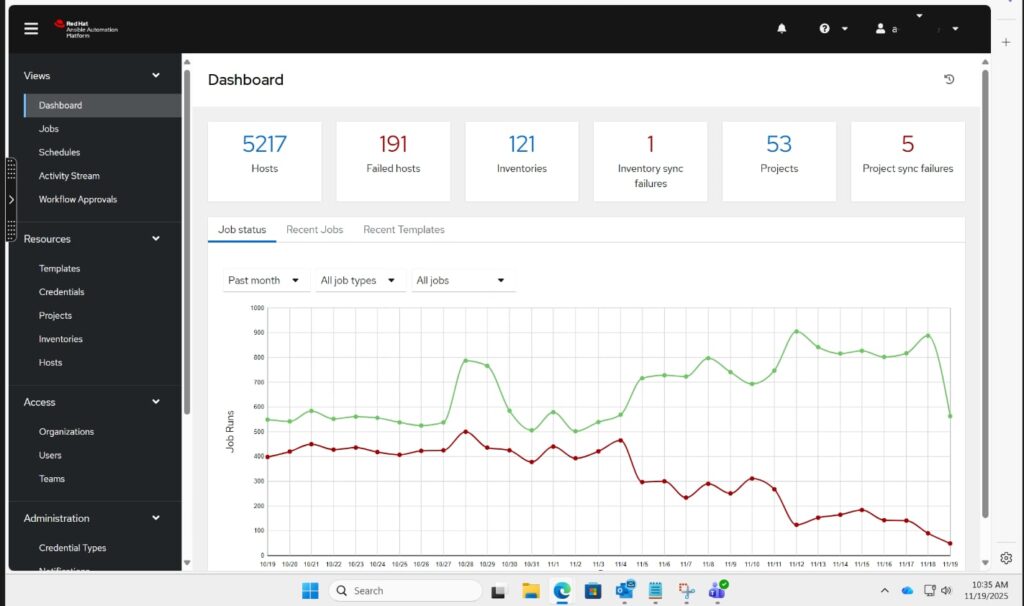
Implementing Ansible Automation Platform for Enterprise Patch Management Across Multi-Environment Infrastructure
Overview A global technology services company was facing challenges maintaining consistent security patching across its multi-environment infrastructure (Production, Staging, Dev, and DR). Manual patch operations took several hours, required weekend maintenance windows, and often resulted in configuration drift between servers. The client approached us to design and implement an enterprise-grade Patch Management Automation solution using...

Blog

Blog
Blog 2
this is blog 2 for test


Blog

Blog
Blog Test 1
this is for test purpose so.